Extract Unstructured Data from PDF Using Document Parser Tool
Now you have the basic theoretical knowledge of document parser template editor tools. It’s time to see this tool in action. In this session, we’ll be going to learn how easy it is to extract only the data that you need by defining a template with just a couple of clicks.
Getting Started with Document Parser Templates
Document parser template editor tool offers a simple and intuitive parsing interface that allows you to build a template for extracting vital data. Before we create our own template and go into the details let me show you one sample PDF file and see how easily you can extract data using pre-made templates.
Open a sample PDF file by clicking on the Local Text PDF or Image button and as its name implies it is a template editor tool. Templates can be quickly created and updated without requiring any special technical knowledge. You can save templates in your local drive using which you can process another same kind of PDF document. This template file is nothing but a set of instructions created in YAML or JSON format.
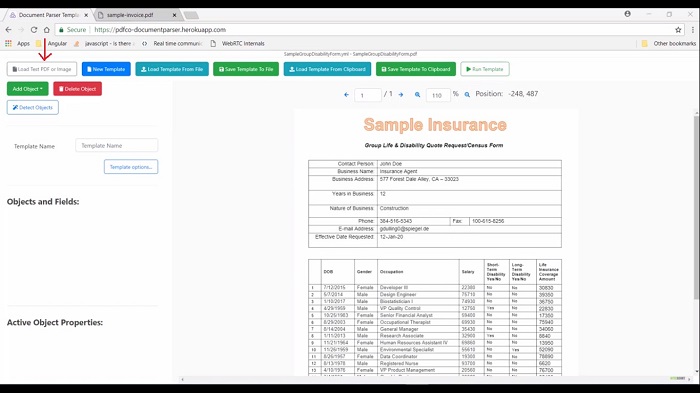
Now open one sample template file and see how it looks like. As you can see here, this template file contains the metadata of the extraction region from which we want to extract the data from the PDF file. Let's move on to document parser tools. For this sample file, I have already defined the template. Now load the template by clicking on the Load Template From File button.
Once the template file is loaded, here you can see the different extraction regions. I have defined it to extract the data like contact person, business name, business address, or the whole table itself. When you execute this template, you will also get the whole table's data. Click on the run template button to see the extracted data. In the Grids tab, you can see our defined fields and its value like phone number, email and you can also see the table data. It's extracted all the table data from the PDF. Currently, these tools support the output data in JSON, YAML, and CSV.
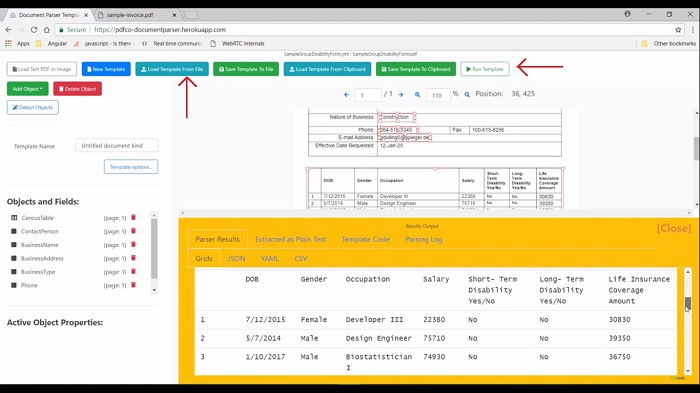
You can also get this extracted data in plain text. For that, you need to click on the Extracted as Plain Text tab and here you can see the data as plain text. You can also achieve the same thing using pdf.co cloud API. It means you can connect document parser tools with other apps or your own apps also. We will see that demo in a very few minutes. Now let's dive some deeper and create our own template.
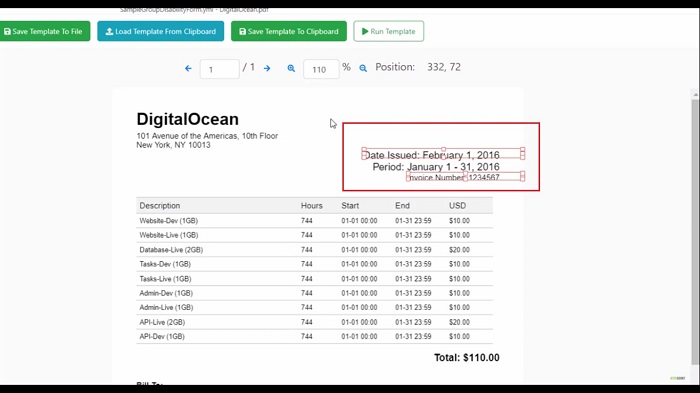
Open another PDF file and as I said earlier that this tool is also able to auto-detect some of the common fields like invoice number, invoice date, etc. Click on the Detect Object button. Here you can see the message five fields were detected and added to the template. Click on the OK button. As you can see here that some of the templates are automatically defined like date issued, invoice number, etc.
How to Proceed with Document Parser
Before we go ahead give the name of the template. You can set some template settings by clicking on the Template options button. If you want to version your template then you can set the template version in the text box. Then you can set culture from the CULTURE drop down as per your need. If your PDF contains scan images then you can set the OCR related settings. Now start defining our own template.
To create the template all you need to do is define the areas within the PDF. You can define the areas either by manually selecting it or by adding different extraction objects. If we talk about the extraction object then this tool provides us six different types of options using which we can extract data as per the requirement. First, when you select the Rectangle Field option, it will add one rectangle extraction region or object. You can place it at a particular location from which you want to extract the data. In our case let me put on this build to location, adjust it such that all data are covered.
You can set the object-related property in the Active Object Properties area. You can also test this individual object by clicking on the TEST Object button. We have got our expected data. Now move ahead and the next object is the rectangle table. When you select this option it will add an object and you can adjust this object as per your need on the table. For example, I want to extract only the first three rows from the table. Once you set this object then you can test this individual object by clicking on the TEST Object button. Here we will get our expected data, this object will extract data based on coordinates.
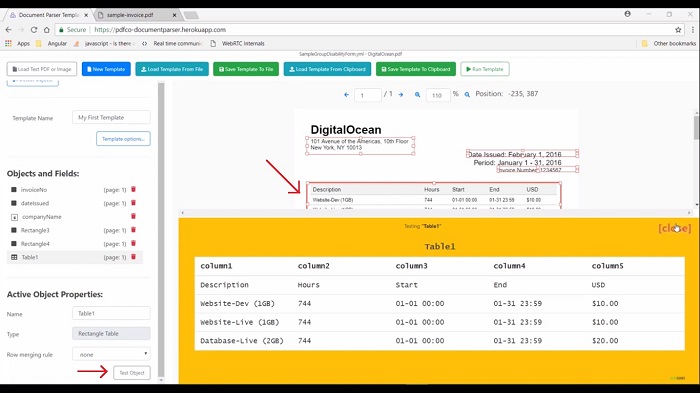
Now move ahead, another one is Static Value Field. If you want to define some static value while extracting the data then you can use this field. For example, add static value for the currency. First, give the name and then define the value. In the same way, you can extract a particular grid cell value using this object. The next important object is the Search-based field. This object scans the document and searches for the text defined in the text box.
Document Parser Features
This tool allows macro-based text extraction, you can set the macro by Autodetect macro and Insert macro button. If I select the zip number which is of course a number. When I click on this auto-detect macro button then this tool has automatically detected the number pattern. So I should use number macro. This button is a kind of magical button. It scans the selected area and finds the first matching macros.
This tool uses a lot of macros, if you want to manually add the macros then you can do that by clicking on the Insert macro button. Here you can see the list of macros that have been created for different purposes. Macro is similar to a regular expression just instead of writing a complex regex pattern to detect something.
You can use these ready to use macros, for example, instead of using a regular expression to detect this date you can use or you can select date macros from the list or just use this auto-detect macro button which will automatically find matching macros for that area. Macros are the kind of powerful but easier replacement for the regular expression. Now let's continue with our search-based field object. This object selects an only text that matches a given pattern with the option to include preceding or trailing text.
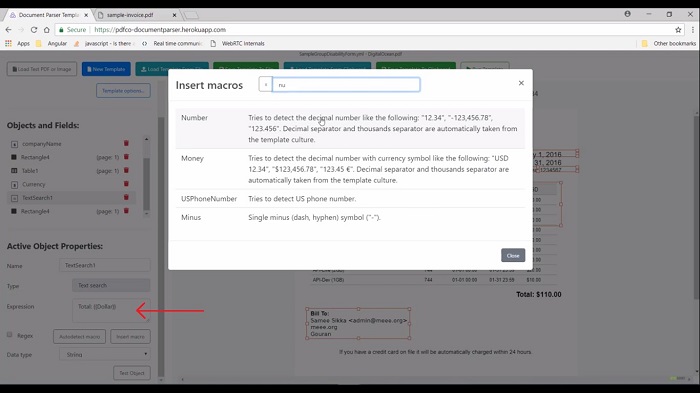
For example, create a template for this total. As you can see that this word starts with the total followed by colon, space, dollar sign, and then there is a number. Now write the expression in this text box. First, we will write total followed by colon and space. Add the macro for this dollar symbol and after the dollar sign, there is a number. Now add the macro for number and if I test this object then I will get the value.
In the same way, all these objects allow the templates to be flexible, simple, and powerful. We can continue defining templates until we have selected all of the text which is important in the PDF to extract. Then you need to run the template through the run template button. Click on the run template button. Here we have our extracted data like invoice number, date issued, company name, our static value currency which is USD, and total extracted table data. The same data is in JSON and CSV too. You can also achieve the same thing using PDF.co cloud API.
Document Parser SDK Document Parser API
Video Tutorial:
Other useful articles:
- What is PDF
- PDF Contents Explained
- PDF.co REST API for Data Extraction
- Document Parser Template Editor
- Extract Unstructured Data from PDF Using Document Parser
- Extract PDF Data Using Document Parser API
- What is Web API and its Types?
- Web API Advantages and Disadvantages
- What is API Request and How it Works?
- REST vs SOAP
- Examples of API
- History and Purpose of APIs
- How is API Documented?
- Layers of APIs
- Protocols of API
- Uses of APIs
- What is API Used for?