PDF Contents Explained
Adobe built a PDF as a file type on the foundation of postscript as a printing language. This we have already learned in the previous session. A PDF document is a data structure composed of a small set of basic types of data objects and it also contains postscript instructions. However, PDF is not a programming language. This session is for those curious people who want to see how a pdf file looks under the hood.
In this tutorial, we will take a look at PDF internals in brief. A PDF document can be defined as a collection of objects which describe how one or more pages must be displayed. This collection of objects can also consider additional interactive components and application data at a higher level.
How to Manage PDF Elements
To manage these elements PDF realizes the adobe imaging model inherited from the postscript language. Objects and components are managed through page content strings which contain operators and operands. At a higher level, the page description is enabled by means of language which complies with the imaging model.
This PDF imaging model enables the description of text and graphics in a device-independent and resolution-independent manner. To improve performance for viewing PDF defines a more structured format that is used by most postscript language programs. Now have you ever opened a PDF in a text editor? Before we go ahead first let us open a PDF file in the text editor and see how exactly it looks like.
The PDF file which we are going to open in the sublime text editor. Just right click on that file name and open it in the sublime editor. These are the row objects that define the structure and content of the document but here the point is you can see how difficult it is to understand what is going on inside though this PDF file is relatively small and does not contain a lot of objects and streams. You can imagine how complex it is if it contains a lot of objects. It is not just a simple text file but it will make a little more sense once you understand what exactly it is. Let's jump into the basic structure of a PDF file.
PDF File Format Overview
The PDF file format is text with some binary data mixed in. PDF files are either 8-bit binary files or 7-bit ASCII text files. A PDF file will initially have these structures however if the file is updated or edited additional elements may be added to the end of the file.
A PDF file is basically broken down into four parts, a header, body, cross-reference table, and a trailer. The file header is probably the most simple section in the PDF file structure. The PDF file starts with the header part which will denote the PDF specification version of the PDF files.
PDF Elements Explained
For example, percentage PDF dash followed by PDF version number and in the next line there are some garbage characters which start with the percent sign and followed by 4 bytes of garbage characters. Here percent sign denotes comment starts and these garbage characters or binary characters are to show the PDF reading application that the PDF has binary data. The file which we opened in the sublime editor a few minutes ago, this highlighted portion is referred to as a header.

Next is the trailer, for any PDF software management application, this is the entry point to read the file. This is the last part of the PDF file structure but PDF reading software read it first. It contains the detail of the cross-reference table, conceptually the PDF file is a tree-like model where the trailer is the root node containing the address of the cross-reference table. The cross-reference table has the offset of each object which refers to the indirect objects present in the body part.
The root object will become the root node of a tree, the derived objects of the root object are placed as sub-nodes if they exist. Otherwise, it will directly establish a link as a sub-node with a cross-reference table. The indirect objects are read one by one and establish a link with sub-nodes likewise all objects are connected to a tree. Now let's go to that PDF file that we have already opened in the sublime editor. The trailer section is recited at the end of the file. Scroll down to the end of the file and this is the trailer section. Now the trailer section has three parts. The first part has the keyword trailer followed by a dictionary that holds values for certain fields.
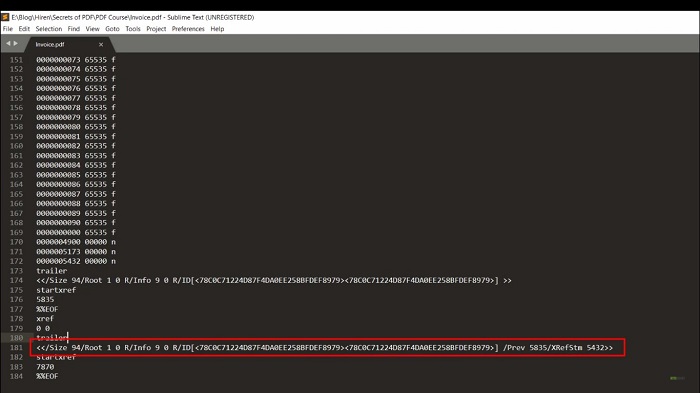
The second part has the keyword start Xref which stands for cross reference and in the next line, there is a number. The number denotes how far the last section of the cross-reference table is from the start of the file. The third part has the value %%EOF which indicates the end of the file. Now let's try to understand this trailer dictionary. Here this size indicates the total number of entries in the cross-reference table. In our example, there are 94 entries including an entry for object 0 roots.
The root is the root object and contains references to the PDFs catalog. This catalog is the one that is used by PDF reading software. When a PDF gets an incremental update in addition to the data being added a new cross-reference table section is created. This new section contains entries for all the objects that were deleted, replaced, or changed. Now let's move on to the next section which is the cross-reference table.
The cross-reference table section contains the location of each object within the PDF file. By looking at the entries in this table the PDF reading application, for example, adobe reader can easily locate an object within the file. Again open that PDF file in the sublime editor for better understanding. In this PDF file, the cross-reference table section presides over here. The cross-reference table can have one or more sections, each section beginning with the word Xref which is cross-reference.
Then in the next line, there are two numbers separated by a single space. The first number identifies the first object in the current subsection while the second number gives the number of objects in the current subsection. For a PDF file that has been created for the first time or a PDF file that has not been incrementally updated there shall be only one subsection and the object numbering starts with zero. Then this section contains the entries for each object. Each entry shall be exactly 20 bytes long.
This section is divided into three parts, in the first part, the 10 digit number indicates how far the object is from the start of the file. For example, in our case, the value 10 denotes that the object is 10 bytes from the start of the file and the next five digits indicate the generation number, and the last part contains either character F or character N. It means if a line ending with an N character it refers to the objects in use while those ending with an F character indicates that the object is free. It has been removed and that its number can be used by another future object.
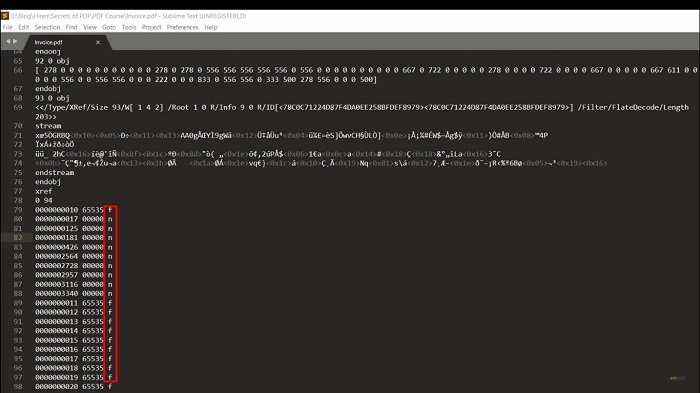
Now the same way here objects 2 and 3 are 17 and 125 bytes away from the start of the file respectively. This N indicates they are in use. Now let's move on to the next section, the body which generally contains the most part of the PDF. This section is made of a list of objects which describes how the final document will look and these objects typically include text streams, fonts, images, other multimedia elements, etc.
They are called cause objects. Here objects may be either direct or indirect. Direct objects are just inline values whereas indirect objects are numbered with an object number and a generation number. They define between the obj and endobj keywords if residing in the document root. The PDF file format specification is publicly available here in the mentioned URL and can be used by anyone interested in the PDF file format. There are almost 100 pages of documentation for the PDF file format.
In the next tutorial, we will study what kind of objects PDF can contain and we will read and manipulate PDF files using the tools provided by ByteScout.
Document Parser SDK Document Parser API
Video Tutorial:
Other useful articles:
- What is PDF
- PDF Contents Explained
- PDF.co REST API for Data Extraction
- Document Parser Template Editor
- Extract Unstructured Data from PDF Using Document Parser
- Extract PDF Data Using Document Parser API
- What is Web API and its Types?
- Web API Advantages and Disadvantages
- What is API Request and How it Works?
- REST vs SOAP
- Examples of API
- History and Purpose of APIs
- How is API Documented?
- Layers of APIs
- Protocols of API
- Uses of APIs
- What is API Used for?